1. Abstract
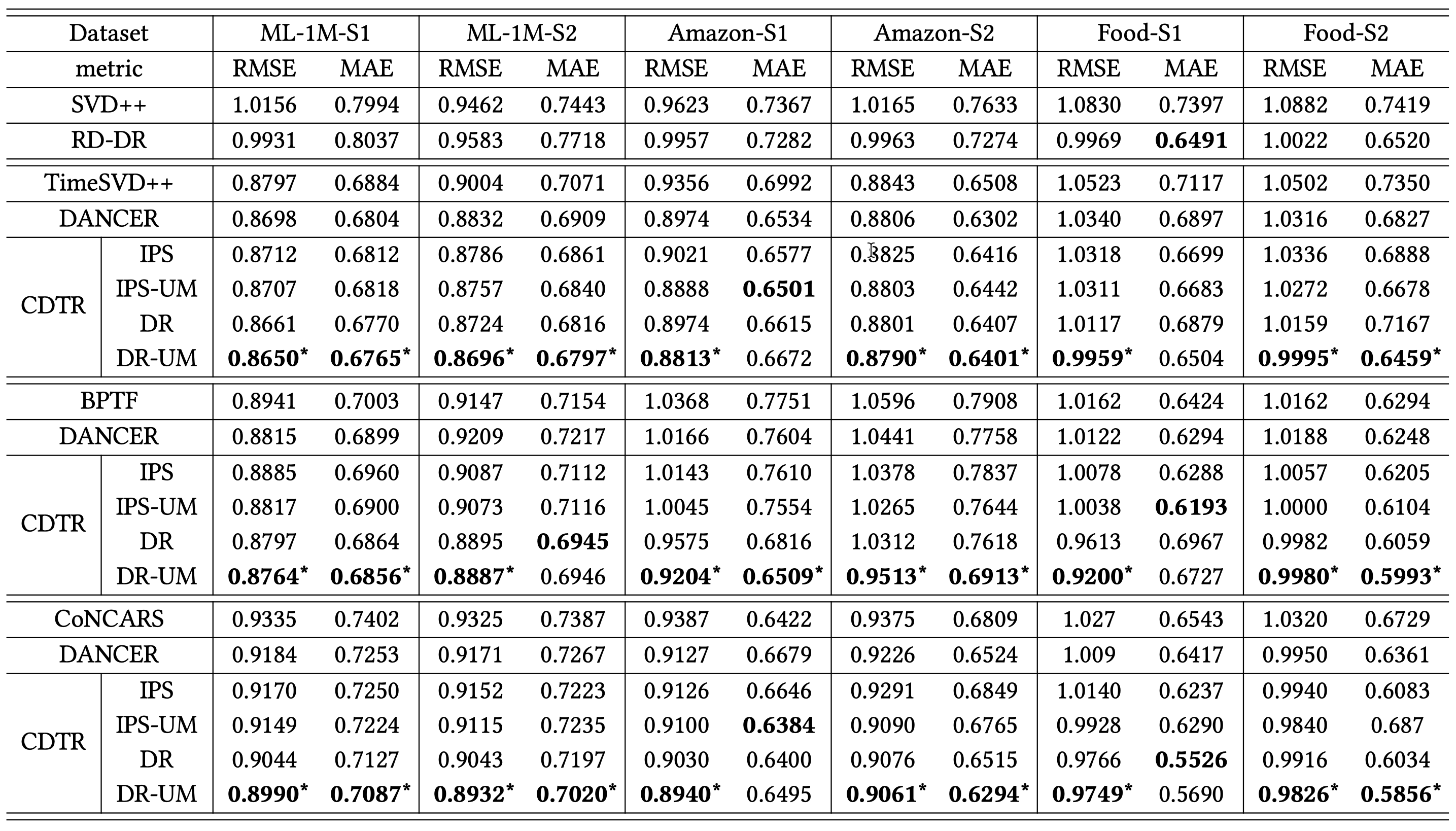
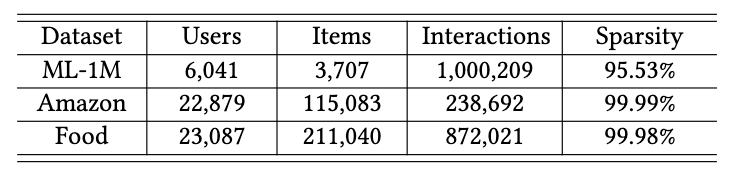
Time-aware recommendation has been widely studied for modeling the user dynamic preference. While, in the past few decades, a lot of promising models have been proposed, an important problem has been largely ignored, that is, the users may not evenly behave on the timeline, and the observed datasets can be biased on the interaction time, which may degrade the model performance. In this paper, we propose a causally debiased time-aware recommender framework to more accurately learn the user preference. In specific, we firstly formulate the task of time-aware recommendation by a causal graph, where we identify two types of biases on the item- and time-levels, respectively. Then we define the ideal unbiased learning objective. To optimizable this objective, we propose a debiased framework based on the inverse propensity score (IPS), and also extend it to the doubly robust method. For both of these methods, we theoretically analyze their unbiasedness. Considering that the user preference in the recommendation domain can be quite diverse and complex, which may result in the unmeasured confounders, we develop a sensitive analysis method to obtain more accurate IPS. We theoretically draw a connection between this method and the idea learning objective, which to the best of our knowledge, is the first time in the research community. We conduct extensive experiments based on {three} real-world datasets to demonstrate the effectiveness of our model.